超節點(SuperPod)是近年來為應對AI大模型訓練與推理需求而發展起來的新型算力基礎設施架構,它透過高速互連技術將大量運算單元(如GPU、TPU、NPU等)緊密整合,建構一個高頻寬域(HBD)。
具體來說,超節點是指在一個實體機櫃或一組緊密耦合的計算單元內部,透過高密度整合計算單元和專用的高速互聯技術,實現近似單機性能的超大規模平行計算系統。
它旨在突破傳統伺服器內部以及伺服器之間透過PCle或標準乙太網路互聯的頻寬和延遲瓶頸,將數十甚至數百個加速器緊密連接,形成一個邏輯上的超大伺服器,以支援張量並行、專家並行等對內部通訊要求極高的平行計算任務。
超節點運算架構的關鍵特徵包括:
●高密度算力整合:在有限空間內整合大量GPU或其他AI加速器,提供極致的運算密度。
●高速互聯:採用NVLink、InfiniBand等高速互聯技術,實現GPU之間以及GPU與網路之間的高頻寬、低延遲通信,消除資料傳輸瓶頸。
●算力與網路深度融合:網路不再只是資料的傳輸通道,而是與運算緊密結合,實現網路感知運算、網路融合運算,甚至運算重塑網路。例如,在超節點內部,透過引入節點內交換晶片,增強卡間P2P頻寬,有效提升節點內網路傳輸效率。
●統一資源管理與調度:實現運算、儲存與網路資源的統一納管與融合路由調度,提升資源利用率與管理效率。
目前業界典型的超節點方案包括:
(一)英偉達DGX SuperPOD(以NVL72為例)英偉達作為AI加速領域的領導者,其DGX SuperPOD系列是業界廣泛採用的AI超級計算平台。
其中,GB200 NVL72 SuperNode是其最新的代表性產品之一。 GB200 NVL72 SuperNode將36個Grace CPU和72個Blackwell GPU整合到一個液冷機櫃中。
它採用「GPU-GPU NVLink ScaleUp+Node-Node RDMAScaleOut」的互聯方式。 ● Compute Tray:整個系統包括18個Compute Tray,每個Compute Tray包含2個GB200超級晶片,每個GB200超級晶片又包含2個Blackwell B200 GPU和1顆Grace CPU,整個機櫃共72個B200 GPU和36個Grace CPU。
透過NVLink與NVLink-C2C技術,實現GPU之間以及GPU與CPU之間的高速記憶體共享與資料傳輸。單一Compute Tray提供7.2TB/s(單向28.8Tb/s)頻寬,NVL72整機櫃的Compute Tray提供129.6TB/S的NVLink頻寬。
● Switch Tray:共包含9個Switch Tray,每個Switch Tray內建2顆NVSwitch晶片,整個機櫃提供18個NVLink Switch晶片。整機櫃後部透過線纜將ComputeTray和Switch Tray進行互聯。
單一Switch Tray提供14.4TB/s(單向57.6Tb/s)頻寬,NVL72整機櫃的Switch Tray提供129.6TB/s的NVLink頻寬。這樣超節點整機櫃Compute Tray的GPU和Switch Tray的交換晶片之間就可以全連接。
● Scale Up:NVL72內部採用NVLink5和NVSwitch建構Scale Up網絡,提供極高的頻寬(每個Compute Tray透過NVLink/NVSwitch具有7.2TB/s的ScaleUp連接頻寬)和超低時延(銅電纜連接節省了光模組引入的延遲)。
所有GPU可以存取整個超節點其他GPU的HBM記憶體和Grace CPU的DDR內存,實現統一記憶體空間。
● Scale Out:透過CX8800Gbps RNIC接入InfiniBand RDMA Scale Out網絡,實現多個NVL72 SuperNode組成更大規模的SuperPOD(例如8個DGX GB200NVL72組成一個包含576塊B200 GPU的SuperPOD)。
(二)華為CloudMatrix 384CloudMatrix 384是華為推出的超大規模AI超節點解決方案,由384顆昇騰910C NPU晶片透過全連接拓撲結構互聯而成。它創新地提出了對等運算架構,將匯流排從伺服器內部擴展到整機櫃甚至跨機櫃。
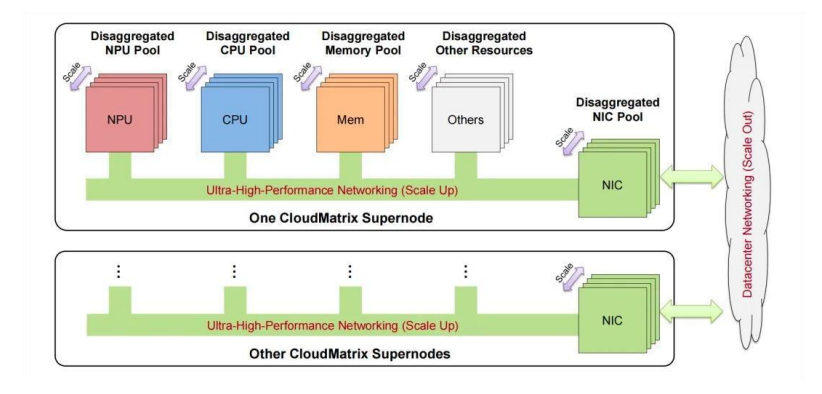
● Compute Tray: 每個Compute Tray包含8塊910C NPU,並且內建了7個L1-HCCS-SW交換晶片(上聯Scale Up)+1個CDR交換晶片(上聯Scale Out)。
910C NPU採用Chiplet技術,整合了2顆910B和8顆HBM2e內存,單卡算力達到FP16781.25 TFLOPS,內存頻寬3.2TB/s。
每張NPU基於HCCS(High-speedComputing Cluster System)GPU-GPU私有高速互聯協定使用8個通路分別連接到L1-HCCS-SW交換晶片,實現無阻塞頻寬收斂比。 ● Switch Tray: 每個Switch Tray(CloudEngine 16800交換機)有16個業務槽,每個業務槽最大支援48個400G接口,整台支援768個400G接口。採用單層扁平化拓撲,建構NPU全互連(All-to-Al1)拓樸結構,消除傳統網路的頻寬瓶頸。
● Scale Up:CloudMatrix384的Scale Up頻寬高達269TB/s,是NVL72的2.1倍。因物理距離限制,採用400G低功耗光模組(LPO),省略了傳統DSP晶片以降低延遲和功耗。 ● Scale Out:採用Spine-Leaf 8導軌拓撲,透過400G光模組建構Scale Out網絡,實現超節點間的互聯,總頻寬是NVIDIA NVL72的5.3倍。
(三)ETH-X由ODCC牽頭,聯合中國信通院、騰訊等單位發起的ETH-X計畫可以支援單一超節點64卡的運算能力,和英偉達的私有NVLink方案不同,ETH-X採用更開放的RoCE方案。
● Compute Tray:每個Compute Tray包含4張GPU和1個X86 CPU,CPU和GPU之間透過PCle Switch對接。整個機櫃共64張GPU.同時每個Compute Tray提供4個NIC用於Scale Out方向的擴展。
● Switch Tray: 每個Switch Tray包含1顆支援RoCE的高效能51.2Tbps乙太網路交換晶片,整個機櫃提供8個Switch晶片.GPU和Switch晶片支援100G serdes。
ETH-X整機櫃GPU互聯頻寬為204.8Tbps.8個Switch Tray支援409.6Tbps的頻寬,一半用於超節點櫃內連接GPU,另一半的頻寬用於背靠背連接旁邊機櫃的超節點或透過L2HB Switch做更大的HBD域Scale Up擴充。
Intel Gaudi3GPU提供4.8Tbps的頻寬,整個超節點機櫃需要12個Switch Tray。 ETH-X也支援Switch Tray沒有外部Scale Up擴充口的方案,所有serdes連接都用於櫃內互聯,只需要4個2U高的Switch Tray。