●直面算力利用效率低下難題,華為發布Al容器技術Flex:ai華為在上海舉辦「2025 AI容器應用落地與發展論壇」,會上正式發布並開源了創新AI容器技術Flex:ai。
目前,業界算力資源的平均利用率僅30%至40%,據華為介紹,華為Flex:ai是基於Kubernetes容器編排平台構建的XPU池化與調度軟體,透過算力切分技術,將單張GPU/NPU算力卡切分為多份虛擬算力單元,切分精準至10%。
此技術實現了單卡同時承載多個AI工作負載,在無法充分利用整卡算力的Al工作負載情境下,算力資源平均利用率可提升30%。
● Al時代需要Al容器技術,華為Flex.ai對標英偉達Run:ai具有獨特優勢傳統容器技術難以適配Al工作負載需求,Al容器作為輕量級虛擬化技術,可打包模型代碼與運行環境實現跨平台遷移,解決環境配置不一致問題,且能按需掛載GPU/NPU算力、優化資源集群利用率。
Gartner表示,目前AI負載大多已容器化部署和運行,據預測,到2027年,75%以上的AI工作負載將採用容器技術進行部署和運行。
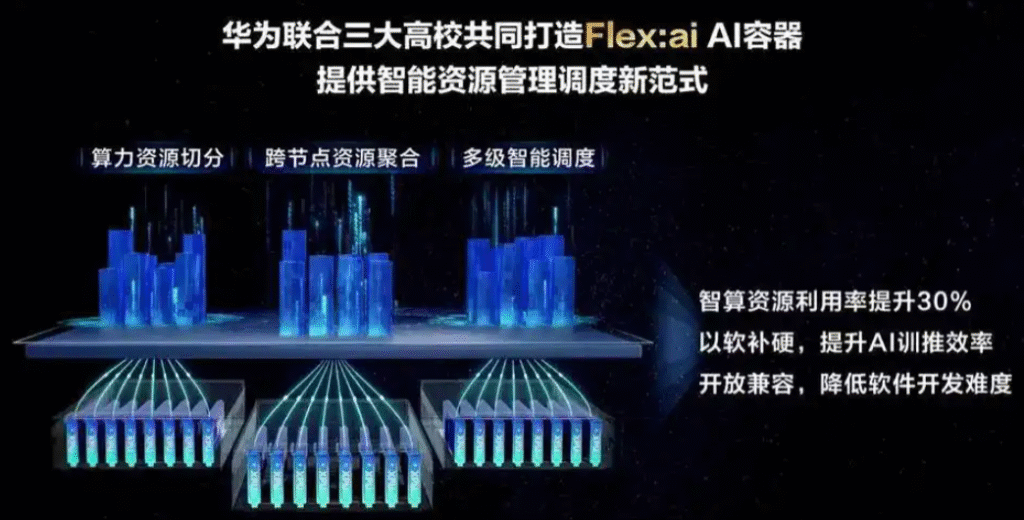
與英偉達今年初收購的Run:ai公司的核心產品相比,華為Flex:ai在虛擬化、智慧調度等方面具備獨特優勢。
具體來看,在本地虛擬化技術中,Flex:ai支援將單一實體GPU/NPU算力卡切割為數個虛擬算力單元,並透過彈性且靈活的資源隔離技術,可實現算力單元的按需切分。
智慧調度方面,Flex:ai智慧資源與任務調度技術,可自動感知叢集負載與資源狀態,結合Al工作負載的優先權、算力需求等多維參數,對本地及遠端的G虛以利PU資源進行全局最優調度,滿足不同AI工作負載對資源的需求。

以軟體補硬體提升Al訓推效率,國產Al生態發展再進階Flex:ai秉承開源與相容異構算力的理念,進一步強化國產算力實力。
Flex:ai將在發布後開源在魔擎社群中,與華為此前開源的Nexent智能體框架、AppEngine應用程式編排、DataMate資料工程、UCM推理記憶資料管理器等Al工具共同組成了完整的ModelEngine開源生態。
另外,與英偉達旗下Run:ai只能綁定英偉達算力卡不同,Flex:ai透過軟體創新,可實現對英偉達、昇騰及其他第三方算力資源的統一管理和高效利用,有效屏蔽不同算力硬體之間的差異,為Al訓練推理提供更有效率的資源支援。
為啥非得升級AI容器?傳統容器問題在哪?首先得承認,容器技術和AI本來就是「好搭檔」。容器能把模型代碼、運行環境打包成一個獨立的“鏡像”,不管你在哪個平台上跑,環境都一樣,解決了“換個電腦就跑不起來”的老問題。
而且容器能按需分配算力資源,用完了還能回收,不浪費集群資源。 Gartner的分析師早就預測過,到2027年,75%以上的AI工作負載都會用容器技術部署,這趨勢已經很明顯了。
但問題是,傳統容器技術是為普通計算場景設計的,遇到AI大模型就「力不從心」了。
第一個痛點就是「鏡像太大拉不動」。
現在的大型語言模型(LLM),容器鏡像輕鬆就超過10GB,多模態模型的鏡像甚至能到TB級別。傳統容器要拉起這麼大的鏡像,得等好幾個小時,嚴重耽誤AI專案的進度。
第二個痛點是「管不了智能算力」。
傳統容器只能管CPU、記憶體這些通用資源,對GPU、NPU這些異構智算資源完全沒轍。沒辦法把算力卡切分成小單元,也沒辦法智能調度,結果就是即使一個很小的AI任務,也得佔一張整卡,造成大量算力閒置。
例如一家公司做個簡單的AI文字分類,本來用10%的算力就夠了,卻不得不佔一張GPU卡,剩下90%的算力就白白浪費了。
第三個痛點是「調度太死板」。傳統容器的資源調度是“固定分配”,例如給某個任務分配2核CPU、4GB內存,就一直是這個配置,沒法根據任務的實際需求動態調整。
但AI工作負載的需求變化很大,例如模型訓練初期可能需要大量算力,到後製算力需求就降下來了。
傳統容器沒辦法感知這種變化,要嘛一直佔多餘算力,要嘛算力不夠導致任務卡頓。 AI時代Flex:ai可有效緩解這些痛點。